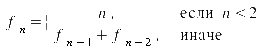
Т-система с открытой архитектурой
( OpenTS )
Краткое введение для пользователей
(Draft от 01.07.2003 в стиле опубликованной главы о Т-системе в книге
“Параллельное Программирование”)
Т-система — оригинальная российская разработка, которая была начата в Институте программных систем РАН в начале 80-х годов.
В последние годы Т-система развивается в рамках суперкомпьтерной Программы «СКИФ» Союзного государства Сегодня Т-система претерпевает переход из категории экспериментальных в разряд промышленных систем.
Т-система была успешно опробована как на достаточно широком круге задач, так и на вычислительных установках различного масштаба: от многопроцессорных PC до вычислительных комплексов с различной архитектурой и разной мощности (различные многопроцессорные Linux/Intel-кластеры, терафлопная российская установка МВС-1000М).
Как нам кажется, эта технология обладает значительным потенциалом для дальнейшего развития и расширения области применения.
Все современные технологии распараллеливания призваны автоматизировать переход от программы, записанной на языке, удобном для человека, к параллельному алгоритму, который при соответствующей аппаратной поддержке позволяет получить выигрыш в производительности по сравнению с последовательным выполнением аналогичной программы на монопроцессоре.
В силу сложности этой задачи, на пути распараллевания возникают те или иные проблемы, и никем пока не предложен универсальный способ для их решения. Различные подходы разнятся своими ключевыми идеями, которые в совокупности и обуславливают сильные и слабые стороны каждой конкретной технологии, и как следствие этого, имеют ту или иную область своего эффективного применения.
Наиболее характерной чертой Т-системы является использование парадигмы функционального программирования для обеспечения динамического распараллеливания программ. При этом в Т-системе найдены и реализованы весьма эффективные формы как для собственно организации параллельного счета (синхронизация, распределение нагрузки), так и для сочетания функционального стиля с императивными языками программирования (в Т-системе используется гладкие расширение привычных для большинства программистов языков C, C++, Fortran).
Наиболее явно преимущества Т-системы проявляются на задачах, в которых:
Априорно (до начала счета) неизвестно, как распараллелить работу.
Вычислительная схема близка к функциональной модели, то есть может быть эффективно представлена с помощью совокупности функций, рекурсивно вызывающих друг друга.
Как известно из общей теории функционального программирования, базирующейся на лямбда-исчислении, окончательный результат редукции (вычисления) лямбда-выражения не зависит от порядка редукции (вычисления) входящих в него редексов (подвыражений)1). Это дает прямой и вполне очевидный метод для распараллеливания чисто функциональных программ, то есть программ, построенных из «чистых» функций без сторонних эффектов: нужно в каждый момент времени выделять готовые к вычислению подвыражения и распределять их по имеющимся процессорам.
Давайте теперь проследим за тем, каким образом отправляясь от этой (довольно-таки простой) идеи можно получить полноценную среду для динамического распараллеливания программ.
Прежде всего, нужно найти эффективное представление в оперативной памяти мультикомпьютера для функциональных выражений, то есть эффективное представление для набора вида «функция, ссылки на аргументы». Поскольку сейчас повсеместно используются адресные компьютеры, то за основу для такого представления естественно взять граф, узлы которого представляют вызванные функции, а ребра представляют собой отношение «подвыражение—выражение» (или, в терминологии функционально-потоковых схем, отношение «поставщик—потребитель»).
Далее, необходимо реализовать эффективную схему распределения готовых к исполнению гранул параллелизма, которыми здесь и являются наборы «функция, ссылки на аргументы» по процессорам мультикомпьютера, обеспечить доставку данных по высокоскоростным коммуникациям и корректное разделение данных в пределах каждого SMP-вычислителя.
Разумеется, нужно также обеспечить начальное преобразование исходного текста программы с целью получения вышеупомянутого графа в момент запуска. Дальнейшее преобразование (автотрансформация) графа будет производиться в процессе параллельного счета.
Оказывается, что достаточно ввести в императивный язык программирования (например, в язык C++) понятие неготового значения, введя дополнительное ключевое слово (например, tval) в качестве необязательного атрибута переменных, и функциональная семантика легко и ненавязчиво для программиста проникает в программный код. Еще небольшое число ключевых слов потребуется для необязательных атрибутов, обозначающих:
tfun— Т-функции, то есть функции без побочных эффектов, вызовы которых можно вычислять параллельно;
tout— выход Т-функции (аргумент, для возвращения посчитанного значения);
и др. (подребнее см. документ “описание языка T++”)
Диалект, полученный из языка C++ добавлением указанных ключевых слов, будем называть языком T++. Язык Т++ позволяет использовать привычную для многих императивную нотацию для записи программ в функциональном стиле. Кроме того, он позволяет получить весьма простой способ начальной трансформации программы в вычислительный граф.
Для того чтобы ознакомиться с базовыми конструкциями Т-системы и языка T++, мы рассмотрим два простых примера: числа Фибоначчи и рекурсивный обход древовидной структуры данных.
Рассмотрим (Рис. 1) программу вычисления n-ого числа Фибоначчи. Вычисление реализовано не самым оптимальным образом — при помощи «прямолинейного» кодирования (см. функции cfib и fib) известного рекурсивного определение для чисел Фибоначчи:
В программе, с использованием ключевого слова tval определены переменные, способные хранить как обычное, так и неготовое значение. В момент, когда их адреса передаются в Т-функцию fib (вызовы fib в строках 18, 19 и 36), выполнение вызывающей функции не останавливается (не дожидается возврата управления из вызванной функции), а продолжает выполняться дальше. При этом:
В момент вызова fib (строки 18, 19 и 36) соответствующая переменная становится «неготовой». Она содержит специальное неготовое значение. В дальнейшем это неготовое значение будет заменено обычным (готовым) значением: а именно в тот момент, когда вызванная функция fib посчитает и вернет в переменную свой результат (строка 15 или 20).
Только что порожденный вызов Т-функций fib (строки 18, 19 и 36) является новой гранулой параллелизма, готовой к вычислению. Она помещается в очередь, откуда локальные вычислительные процессы-исполнители (работающие на каждом вычислительном узле кластера, в количестве, равном числу процессоров в этом SMP узле) черпают работу сначала для себя, а затем (в случае полной локальной загрузки) и для других свободных вычислительных процессов в кластере.
Обращение к неготовым переменным на чтение (за значением) блокирует процесс вычисления функции.
Неготовые переменные, таким образом, являются средством синхронизации и посредниками при создании новых узлов редуцируемого вычислительного графа. Существенно различаются ситуации обращения к неготовым переменным на чтение (доступ за значением) и на запись (доступ для присваивания):
как уже говорилось, при чтении происходит блокировка процесса вычисления, осуществившего такое обращение, и ожидание, когда переменная обретет готовое значение;
при записи обычного значения в неготовую переменную она становится готовой для всех потребителей ее результата, а ранее заблокированные на данной переменной процессы— разблокируются.
001 #include <txx>
002
003 #include <stdio.h>
004 #include <stdlib.h>
005
007 int cfib (int n) {
009 return n < 2 ? n : cfib(n-1) + cfib(n-2);
010 }
011
012 tfun int fib (unsigned n)
013 {
014 if (n < 32) {
015 return cfib(n);
016 } else {
017 return fib(n-1) + fib(n-2);
021 }
022 }
023
024 tfun int main (int argc, char* argv[])
025 {
026 int n;
028 if (argc < 2) {
029 fprintf(stderr,"Usage: %s <number>\n", argv[0]);
032 return -1;
034 }
035 n = atoi(argv[1]);
038 printf("fib(%d) = %d\n", n, (int)fib(n));
039 return 0;
040 }
Рисунок 1. Программа вычисления чисел Фибоначчи
На примере программы вычисления чисел Фибоначчи мы познакомились с языком Т++ — входным языком Т-системы.
Язык T++ разработан как синтаксически и семантически гладкое расширение языка C. Под «гладкостью» здесь понимается то, что дополнительные конструкции синтаксически и семантически увязаны с конструкциями основного языка C. Явные параллельные конструкции, понимаемые в привычном смысле, в языке T++ отсутствуют, например, программист не указывает, какие части программы следует выполнять параллельно. Т-функции указывают прототипы (шаблоны) возможных гранул параллелизма— реально гранулы параллелизма возникают и обрабатываются Т-системой во время работы программы, во время вызовов Т-функций. Указаниями для организации параллельного счета являются элементы расширения синтаксиса и семантики языка, которые наиболее адекватно отражают архитектуру, функциональность и назначение Т-системы, а также зависимости по данным между отдельными счетными гранулами.
Ключевые слова языка T++ и используемые специфические функции и макроопределения, свойственные языку T++, перечислены и описаны в документации языка T++. Набор таких ключевых слов невелик, и освоить его не составит труда для любого программиста, привыкшего к написанию программ на языке C++.
Основные ключевые слова языка T++, описывающие основные типы данных языка, реализованы как шаблоны, написанные на языке C++, например:
Уже знакомое нам ключевое слово tval реализовано как шаблонный класс TVar<...> языка C++.
Ключевое слово tptr реализовано как шаблонный класс TPtr<...> языка C++. Данное ключевое слово употребляется для описания удаленного указателя, то есть указателя, который содержит в себе не только информацию об адресе в памяти, но и номер вычислительного узла кластера, для которого указывается этот адрес.
И т.д.
Параметризованные классы (шаблоны), определяемые Т-системой, можно непосредственно использовать в коде на языке C++, например, если требуется распараллелить программный модуль, реализованный на языке C++.
Добавленные в язык С расширения выглядят достаточно прозрачными для синтаксиса и семантики языка C. Это позволяет программу на языке T++ разрабатывать и отлаживать без использования Т-системы. Для этого достаточно использовать специальный заголовочный файл txx, который переопределяет (с помощью макроопределений) все ключевые слова, добавленные в язык C. Таким образом Т++ программу можно компилировать обычными компиляторами С, выполнять в последовательном (однопроцессорном) режиме и отлаживать, используя штатные однопроцессорные средства отладки.
Данное свойство упрощает первый этап цикла разработки программ, позволяя отлаживать последовательные части реализованного функционального алгоритма в наиболее удобной, привычной для программиста среде.
Отметим, что аналогичная возможность была реализована для языка параллельного программирования Cilk [7].
Рассмотрим программу рекурсивного обхода дерева (Рис. 2 и 3), написанную на языке Т++. На этом примере мы продемонстрируем работу с удаленными (tptr) указателями.
001 #include <txx>
002
003 #include <stdio.h>
004 #include <stdlib.h>
005
006 struct tree {
007 struct tree tptr left;
008 struct tree tptr right;
009 int value;
010 };
011
012 struct tree tptr create_tree(int deep) {
013 struct tree tptr res = new tval tree;
014 res->value = 1;
015 if (deep <= 1) {
016 res->left = NULL;
017 res->right = NULL;
018 } else {
019 res->left = create_tree(deep-1);
020 res->right = create_tree(deep-1);
021 }
022 return res;
023 }
Рисунок 2. Программа рекурсивного обхода дерева.
Структуры
данных и вспомогательные функции
025 tfun int tsum(struct tree tptr tree) {
027 tval int leftSum, rightSum;
028
029 if (tree->left != NULL) {
leftSum = tsum(tree->left);
} else {
leftSum = tree->value;
}
034 if (tree->right != NULL) {
035 rightSum = tsum(tree->right);
} else {
rightSum = tree->value;
038 }
039 return leftSum + rightSum;
040 }
041
042 tfun int main (int argc, char* argv[])
043 {
044 struct tree tptr tree = create_tree(12);
047 printf("sum = %d\n", (int)tsum(tree));
048 return 0;
049 }
Рисунок 3. Программа рекурсивного обхода дерева. Основной код
В этой программе дерево структур с типом tree сначала порождается функцией create_tree, а затем обходится в рекурсивной функции tsum. Точно так же, как и в предыдущей программе, происходит распараллеливание на каждой развилке дерева, поскольку сначала порождаются вызовы для левой и правой ветви, и лишь затем происходит обращение к результатам обхода.
Ключевое слово tptr служит для описания глобальных ссылок на неготовые переменные. При операции чтения данных по Т-указателю может происходить ожидание готовности результата и (если нужно) его подгрузка из других узлов кластера, в то время как при операции записи записываемое значение (если нужно) передается по сети в нужный узел кластера, там значение записывается в переменную и, тем самым, соответствующую Т-переменную делает готовой.
Имеющаяся практика реализации программ для Т-системы позволяет рекомендовать организацию разработки программ на языке T++ из следующих этапов:
1.Разработка алгоритма. Верхний уровень алгоритма разрабатывается на базе парадигмы функционального программирования.
2.Разработка кода. При этом решается вопрос о том, какие фрагменты алгоритма, какая часть кода будет реализована на языке T++ в виде Т-функций, а какая часть—реализована в виде привычного последовательно исполняемого кода на стандартных языках последовательного программирования: С, С++, Фортран.
3.Реализация и первичная отладка на однопроцессорном компьютере. Реализуется и отлаживается вся программа на обычном однопроцессорном компьютере. Во время первичной отладки программа выполняются без Т-системы, последовательно (ключевые слова расширений реализуются в «последовательном режиме»), как это обсуждено выше. Широко используются стандартные монопроцессорные средства отладки.
4. Отладка на многопроцессорных установках. После отладки ТС-программы на однопроцессорном компьютере (в последовательном режиме), ее рекомендуется затем отладить на одиночном SMP-компьютере, а затем — на кластере.
5. Тьюнинг. После отладки, при помощи трассировок и профилировок производится различного рода оптимизация кода.
Практика показала, что программисты достаточно быстро усваивают базовые принципы программирования на языке T++, а поэтапный переход от последовательного исполнения к реальному параллельному счету упрощает выявление некорректностей кода, связанных, обычно, со слишком вольным использованием расширений функционального стиля.
При использовании Т-системы, разумеется, надо помнить об особенностях функционирования Т-системы и Т++-программ. Например, следует помнить, что в результате вызова Т-функции может происходить пересылка данных из одного узла кластера в другой.
Т-система по большей части освобождает программиста от таких забот как явная организация параллельных фрагментов программы, их распределение по узлам кластера, синхронизация таких фрагментов, явные операции обмена данными между ними. Однако было бы ошибкой считать, что в Т-системе «автоматизированы» все аспекты организации параллельного счета.
В первую очередь при реализации программ для Т-системы программист обязан адекватно изложить алгоритм в функциональном стиле— описать программу в виде набора «чистых» Т-функций. Кроме этого, он должен стремится выбрать оптимальный размер гранулы параллелизма,— то есть оптимально подобрать среднюю вычислительную сложность Т-функций:
Слишком малая вычислительная сложность определенных программистом Т-функций может привести к слишком большим накладным расходам. Например, это может привести к тому, что потраченное время на передачи Т-функций (и данных для них) в другие узлы кластера окажется большим, чем время счета этой функций.
Слишком большая вычислительная сложность определенных программистом Т-функций может привести к малому количеству порождаемых в процессе счета гранул параллелизма и к неравномерной загрузке вычислительных узлов кластера (особенно в больших установках).
В состав программного обеспечения Т-системы входят
компилятор языка Т++;
ядро Т-системы;
программы поддержки сервисных возможностей (профилирование, трассировка, повторение трассы, отладка).
Следует заметить, что не все компоненты имеют одинаковую степень готовности и отлаженности (особенно в сервисной части пакета).
Использованные в данном проекте подходы к созданию языковых средств в системе динамического автоматического распараллеливания являются современными и популярными в мире параллельных вычислений: многие современные разработки, опираются на идею языковых расширений стандартных языков программирования.
Реализация «гладкого» синтаксиса языка T++ позволяет быстро и эффективно создавать параллельный код, который выглядит красиво, структурно и привычно для любого, программирующего на таких распространенных языках программирования, как C и C++.
Компилятор TGCC для языка Т++ реализован на базе известного свободного компилятора GCC как новый front end (входной язык и входной модуль) этого компилятора. При этом поддержаны все GNU-расширения языка C, раздельная компиляция, возможность использования элементов языка C++ в программах на T++, полный контроль типов в языке T++, возможность проверки средствами GCC синтаксической корректности описаний и вызовов Т-функций, корректное определение и использование сложных Т-типов (например, возможность описать «tptr-указатель на tptr-указатель» и т.д.).
После компиляции при помощи TGCC объектные модули собираются штатным для ОС Linux редактором связи с библиотеками ядра Т-системы и с другими библиотеками, используемыми ядром (например, MPI) или модулями Т-программы.
Хотя идейная сторона функционирования Т-системы достаточно проста, она все же оставляет достаточно большую степень свободы в плане своей практической реализации. Новая версия Т-системы [2, 5] основывается на вполне стройной математической модели и детально проработанной архитектуре программного обеспечения, что (по сравнению с предыдущей реализацией [3, 4]) позволило существенно уменьшить сложность кода и упростить введение полезных расширений.
Как уже упоминалось выше, наиболее эффективным представление функциональных выражений в памяти адресных машин является представление в виде графа. Процесс редукции (вычисления) для случая такого представления называется параллельной редукцией графов и является одним из наиболее эффективных из используемых на практике методов реализации функциональных языков программирования.
В своей классической форме [6, 8,9,10] алгоритмы параллельной редукции графов создавались и реализовывались для SMP-вычислителей, и поэтому их прямые реализации на мультикомпьютерах современной архитектуры (MMP, кластеры) оказывались не так эффективны на практике, как хотелось бы.
Работы над новой версией Т-системы [2,5] были начаты с построения расширения схемы параллельной редукции графов путем введения в нее понятия кластерного уровня. Кратко это выглядит следующим образом.
Состоянием параллельной программы является совокупности всех ее данных, находящихся на узлах кластера. Процесс параллельного вычисления является процессом изменения состояния программы и, в случае параллельной реализации редукции графа, этот процесс определяется параллельными потоками преобразований графа.
Разобьем все преобразования на три класса по следующим признакам:
Собственно вычисления: преобразования, присущие классической схеме редукции графов: создание новых узлов, вычисления узлов, замена взаимодействующих узлов на узел-результат и т.д.
Стратегии, которые совершают эквивалентные преобразования графа, призванные повысить эффективность вычислений.
Пересылки данных графа между узлами кластера— реализованы в Т-системе за счет использования активных сообщений.
Указанные три класса преобразований отвечают трем уровням в организации современной версии ядра Т-системы: (1) SMP-вычислитель; (2) демоны стратегий и их поддержка; (3) коммуникационный уровень Т-системы.
Преобразования второго класса (стратегии) реализованы демонами, следящими за классическим процессом вычисления. В случае обнаружения неоптимальности граф преобразуется так, чтобы его логическое значение (результат работы программы) не изменился, но «физическая» реализация вычисления с большой вероятностью стала бы более эффективной.
Наиболее часто стратегии вставляют функции посылки вычисления из загруженного узла на незагруженный узел кластера с последующим возвратом результата счета. Заметим, что при этом стратегия вставляет тождественную функцию, с точки зрения преобразования величин, которая (при соблюдении очевидных условий) позволяет эффективнее использовать аппаратуру кластера.
Стратегии могут также выполнять и другую важную роль, например, переупорядочивать граф в целях экономии стека и минимизации переключения контекста вычислительных процессов.
Для эффективной реализации равномерного распределения нагрузки по процессорам на каждом вычислительном узле поддерживаются локальные копии так называемого дерева вычислительных ресурсов. Эта системная структура данных позволяет:
всего лишь за несколько машинных команд определить, что простаивающих процессоров в кластере нет;
в противном случае— за несколько сотен машинных команд определить тот узел, который является наиболее подходящим для отправки на него готового к вычислению вызова Т-функции.
Для актуализации локальных копий дерева ресурсов во время счета вычислительные узлы кластера обмениваются сведениями о своей загруженности. Кроме собранной статистики о загруженности, дерево ресурсов может также содержать иную информацию, например характеристики коммуникационных каналов кластера (скорость передачи, задержки), что планируется использовать в последующих версиях ядра Т-системы.
Вычисление функций-пересылок (преобразования класса 3) осуществляется коммуникационным уровнем Т-системы. В свою очередь коммуникационный уровень Т-системы написан с использованием библиотеки MPI.
В современной версии Т-системы пользователю при разработке параллельных программ доступен следующий сервис, не упомянутый в предыдущих разделах2):
1.Мемоизация Т-функций. В текущей версии Т-системы реализована глобальная мемоизация (табулирование) результатов вычисленных некоторых (задается программистом) Т-функций. При этом перед началом вычисления мемоизуемой Т-функции проверяется, не хранится ли в глобальной мемо-таблице ранее вычисленное значение данной функции на данных значениях аргументов. Если в поиск в таблице оказывается успешным, то вместо повторного вычисления функции извлекается из мемо-таблицы ранее посчитанный результат. Мемоизация функций широко используется в функциональном программировании.
2.Возможность использования готовых библиотек параллельных алгоритмов. В текущей версии Т-системы появилась возможность интеграции программы на языке Т++ и ранее разработанных статически распараллеленных вычислительных алгоритмов. Здесь в первую очередь имеется в виду возможность использовать в программах на языке T++ функций из таких MPI библиотек параллельных алгоритмов, таких как ScaLAPACK, ATLAS, Cactus, MODULEF и пр.
3.Профилирование, трассировка Т-программ. В текущей версии Т-системы реализован режим профилирования приложений и его поддержка со стороны компилятора и Т-системы. Это позволяет получать наглядную информацию о последовательности исполнения отдельных операторов, а также о временах, затраченных на исполнение отдельных функций и блоков кода.
4.Трассировка и повторение трасс Т-программ. В текущей версии Т-системы реализуется поддержка двух особых режимов запуска Т-программ:
Режим трассировки Т-программы. В этом режиме в специальный набор данных— в трассу — последовательно записывается информация о событиях (в порядке их возникновения), происходивших на различных узлах кластера во время параллельного выполнения Т-программы. Состав трассы определяет пользователь.
Режим повторения трассы Т-программы. В этом режиме во время выполнения Т-программы обеспечивается на различных узлах кластера ровно тот же самый порядок событий, что был сохранен в трассе во время запуска данной программы в режиме трассировки.
Данные режимы позволяют изучать порядок параллельного выполнения Т-программ (что полезно на этапе тьюнинга) и обеспечивать точную повторяемость порядка параллельного вычисления Т-программ (что важно на этапе параллельной отладки).
5.Check pointing. В текущей версии Т-системы реализуется режим автоматического сохранения состояния Т-программы во вторичную память (checkpointing) и возобновления сохраненного состояния.
Хотя Т-система и переживает период перехода в разряд промышленных систем, однако, еще многие аспекты данного проекта далеки от завершения реализации. Более того, некоторые красивые идеи лежат на поверхности, но еще даже и не начали реализовываться.
В качестве примера назовем библиотеки шаблонов алгоритмов. Идея таких библиотек проста: одной из сильных сторон функционального программирования является возможность эффективной реализации функций высшего порядка, то есть функций, принимающих в качестве аргументов другие функции. В связи с этим возникает естественное желание для известных схем параллельных вычислительных алгоритмов реализовать функции высшего порядка (что можно рассматривать как шаблоны алгоритмов, образцы вычислений), в которых и будет заключена параллельная схема алгоритма.
При этом прикладной программист после анализа конкретной задачи выбирает тот или иной шаблон и, запрограммировав последовательный код для листовых функций (гранул параллелизма) получает готовое решение своей задачи.
Сайт суперкомпьютерной
Программы «СКИФ» Союзного государства
http://skif.pereslavl.ru
Абрамов С.М., Васенин В.А., Мамчиц Е.Е., Роганов В.А., Слепухин А.Ф. Динамическое распараллеливание программ на базе параллельной редукции графов. Архитектура программного обеспечения новой версии Т-системы//Высокопроизводительные вычисления и их приложения: Труды Всероссийской научной конференции (30 октября--2 ноября 2000 г., г. Черноголовка)— М.: Изд-во МГУ, 2000, стр: 261--264, 2000
S.M.Abramov, A.I.Adamowitch, I.A.Nesterov, S.P.Pimenov, Yu.V. Shevchuck Autotransformation of evaluation network as a basis for automatic dynamic parallelizing//NATUG'1993 Spring Meeting "Transputer: Research and Application", May 10--11, 1993
A.I.Adamovich cT: an Imperative Language with Parallelizing Features Supporting the Computation Model “Autotransformation of the Evaluation Network”//Proc. of PaCT-95, St.Petersburg, Russia, September 12--25, 1995; Victor Malyshkin (Ed.); Springer, 1995, LNCS vol. 964, pp. 127--141
V.Roganov and A.Slepuhin, Distributed Extension of the Parallel Graph Reduction. GRACE: Compact and Efficient Dynamic Parallelization Technology for the Heterogeneous Computing Systems//International Conference on Parallel and Distributed Processing Techniques and Applications, June 25–28, 2001, Las Vegas, Nevada, USA
Glasgow Parallel Haskell http://www.cee.hw.ac.uk/~dsg/gph/
The Cilk Project http://supertech.lcs.mit.edu/cilk
Sisal—A High Performance,
Portable, Parallel Programming Language
http://www.llnl.gov/sisal/SisalHomePage.html
J.Darlington, M.D.Cripps, A.J.Field, P.G.Harrison, M.J.Reeve The design and implementation of ALICE: a parallel graph reduction machine, 1987
J.B.Dennis Data flow supercomputers//IEEE Computer, 13(11), 1980, pp. 48–56
1)—Для тех, кто не знаком с теорией функционального программирования, но хочет познакомиться, мы рекомендуем книгу «Функциональное программирование», перевод которой на русский язык был выпущен издательством «Мир» в 1993-м году. Для остальных проведем следующую аналогию: если есть сложное арифметическое выражение, включающее много подвыражений, заключенных в скобки, то эти подвыражения можно вычислять в любом порядке и в каждом случае мы получим один и тот же результат (рассматривается арифметика без ошибок округлений). В теории функционального программирования этот закон арифметики обобщается на произвольные рекурсивные функции.
2)—Для ознакомления с полным перечнем реализованных возможностей следует обратиться к программной документации [1].