Report on the 4-th International
Russian-Indian exhibition-seminar "Mathematical
modeling and visualization", Moscow, September 15-25, 1997
 |
T-system: Programming environment
providing automatic dynamic parallelizing
on IP-network of Unix-computers |
 |
Program Systems Institute of Russian
Academy of Sciences
Research Center for Multiprocessor
Systems
Pereslavl-Zalessky, Russia, 152140
| tel: +7(08535)98.031 |
fax: +7(08535)20.593 |
fax: +7(08535)98.278 |
[ In Russian:
KOI8 |
CP1251(MS-Windows) |
CP866(DOS) |
ISO8859-5 |
Mac
]
Contens
So far, the problem of implementation of parallel computations is mostly
a problem of software rather than hardware.
This paper introduces a software system
for automatic dynamic parallelizing of programs developed
in RCMS of PSI RAS-the T-system. An example of application of T-system
to a task of image rendering using the ray
tracing method is also presented.
We implement automatic dynamic parallelizing using a
new model of organization of the process of computation:
- Functional programming is
considered. A program is a set of pure functions (no side-effect is allowed).
Each function can have multiple arguments and
results. The bodies of functions can be described in imperative
style (in Fortran, C and etc.) It is only important, that:
- all the information from the outside of the function be received only
via its arguments;
- the information from the function be transferred only via explicitly
declared results.
- Functional call of function G
[x,y,z] = G(a,b);
from a process evaluating some other function F
has non-standard semantics (is
carried out as a network function call).
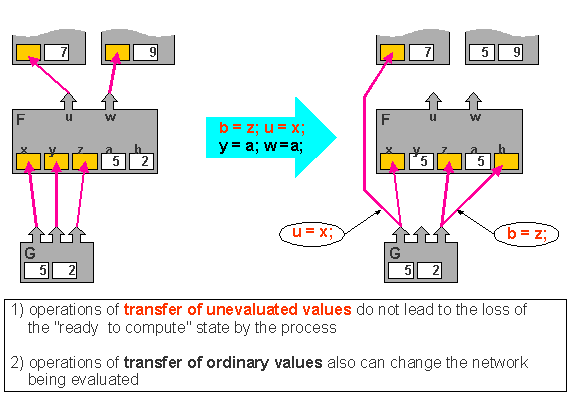
Autotransformation of an network being computed,
as a model of organization of computations, opens an opportunity for automatic
dynamic parallelizing of programs: for the majority of the applications
the organization of the computation in this way provides sufficient number
of processes ready to run, and they can be run in parallel.
The model provides the only mechanism of
synchronization of processes---the mechanism of suspending
and resuming described above.
The closest analogues to
our approach are the Daisy/DSI project (Indiana Univ.), the reduction machine,
and the MDA system (multiprocessor with dynamic architecture, Russia, 1978-1985
years).
The T-system is a software
environment intended to implement the computation model described in the
previous section on a multiprocessor platform.
3.1. Hardware/software platform for T-system
|
The current implementation of T-system runs on a "multicomputer"
that is a TCP/IP network of IBM/PC clones running
OS Linux.
The nearest development plans include:
- support for nodes with SMP hardware architecture;
- ports of T-system to architectures other that IBM/PCs, and to other
Unix clones (and probably under MS Windows NT as well).
3.2. The basic functions of T-system
The main function of T-system is the support of the computation
model "autotransformation of evaluation network." Within
the framework of this function T-system implements the following basic
data structures and operations:
- network call of function;
- delivery of calculated result of function to its consumers;
- operations with unevaluated values (transfer of unevaluated values);
- support of mechanisms of implicit synchronization of processes (suspending,
resuming, etc.).
Each processor element of a multicomputer runs its own instance of T-system---the
so-called co-executive. The
user task is running under the management and with the support of all co-executives.
Functions of T-system related to utilization of all the
computational power of a multiprocessor:
- support of the computation model even when the fragments of evaluation
network are scattered through memory of many co-executives---inter-processor
implementation of the relations "producer-consumer" and the mechanisms
of:
- synchronization of the processes;
- accessing values of the function arguments;
- delivering results to consumers.
- external scheduling---mechanisms of requesting and transferring of
ready to execute processes from one co-executive to other, working on currently
less loaded processor elements of the multicomputer.
3.3. Programming in T-system
Today, the following technique is used for programming applications
under T-system: the programs are developed in the C language using a library
of functions providing an interface to the T-system kernel. The library
provides the programmer with all operations necessary for the considered
computation model.
The nearest development plans include:
- completion of the development of the cT language [PACT'95]---which
is an extension of the C language with the notions of the computation model;
- development of the cT language compiler.
4. Rendering of the 3-D scene images using T-system
|
We have chosen the problem of 3-D scene
rendering using ray tracing as the real problem for demonstration
of the automatic dynamic parallelizing abilities.
4.1. Program structure
The following algorithm is used at the top level of the program:
[image] main(scene, full_screen_description) {
[tree] = render_scene(scene, full_screen_description);
[image] = flatten(tree);
}
[image_tree] render_scene(scene, part_of_screen_description) {
var part1, part2, tree, part_of_img;
if (size_too_big(part_of_screen_description)) {
[part1,part2] = split(part_of_screen_description);
br_node = new(2);
[br_node[0]] = render_scene(scene,part1);
[br_node[1]] = render_scene(scene,part2);
[image_tree] = br_node; // branch in a tree of image fragments
} else {
... allocation of an array part_of_image and filling it by usual
ray tracing algorithm
image_tree = part_of_image; // leaf in a tree of image
// fragments
}
}
[image] flatten(tree) {
... recursive traversal of the tree and composing
the whole image from its fragments.
}
Pay attention to the fact that the information about the number of co-executives,
and the sort of hardware (topology of the network, etc.) is not used in
the program. This is one of the main properties
of our approach:
- T-programs can run without rewriting and even recompilation on various
computing installations with T-system that may differ widely from each
other in the number of processors and the sort of network hardware.
- The programmer does not have to care about the placement of processes
to processors, about the synchronization of processes, etc. The programmer
only has to describe the problem in the functional style on the top level
of program and to take care of large enough computational complexity of
functions in the program (because it's the functions that are grains of
parallel execution in T-system).
4.2. The results of computing experiments
The T-program of ray tracing was run on multicomputers consisting of
one, two, three and four personal computers (IBM PC Pentium 166/32Mb/4Gb).
We rendered the images of scenes of various complexities.
The experiments show that T-system supports high
level of utilization of the multiprocessor's computational power
and low level of overhead.
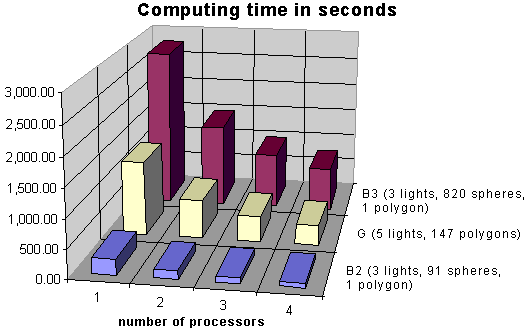
The basic results of experiments with
calculation for three scenes
 |
 |
 |
Scene B2
(3 lights, 91 spheres, 1 polygon) |
Scene G
(5 lights, 147 polygons) |
Scene B3
(3 lights, 820 spheres, 1 polygon) |
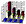 Computing time in seconds
Computing time in seconds |
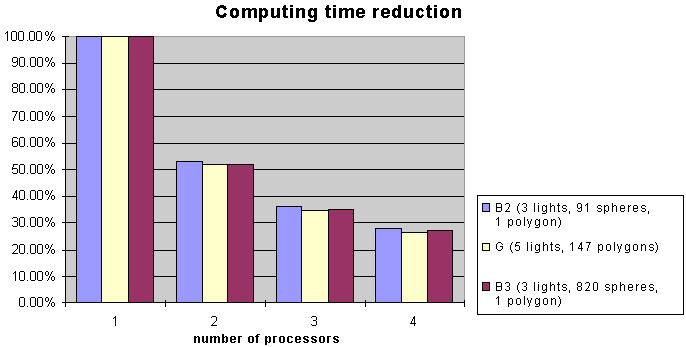
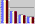 Computing time reduction
Computing time reduction |
| number of processors |
scene B2 |
scene B3 |
scene G |
number of processors |
scene B2 |
scene B3 |
scene G |
| 1 |
278.1 |
2,785.9 |
1,295.2 |
1 |
100.0% |
100.0% |
100.0% |
| 2 |
148.0 |
1,443.5 |
671.9 |
2 |
53.2% |
51.8% |
51.8% |
| 3 |
100.0 |
976.8 |
450.4 |
3 |
35.9% |
35.0% |
34.7% |
| 4 |
77.9 |
747.6 |
345.6 |
4 |
28.0% |
26.8% |
26.6% |
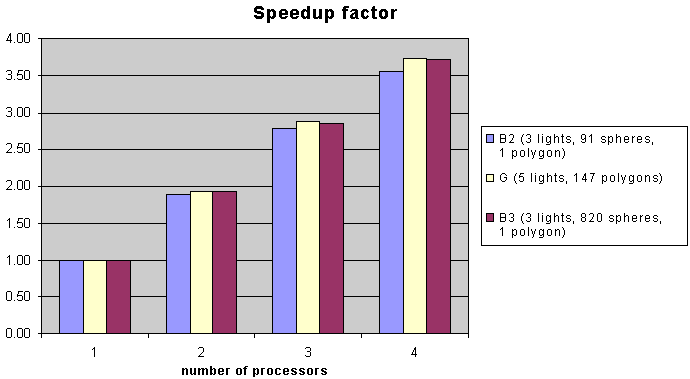
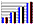 Speedup factor
Speedup factor |
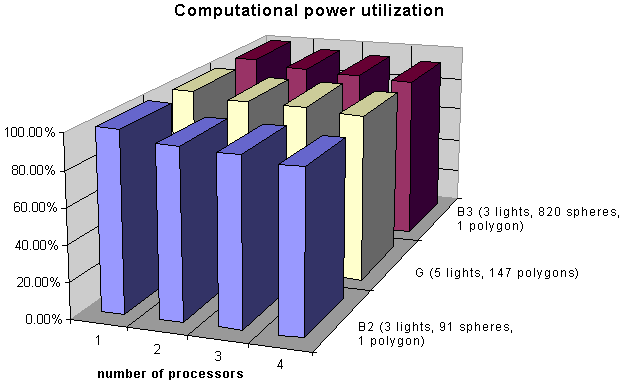
 Computational power utilization
Computational power utilization |
| number of processors |
scene B2 |
scene B3 |
scene G |
number of processors |
scene B2 |
scene B3 |
scene G |
| 1 |
1.00 |
1.00 |
1.00 |
1 |
100.0% |
100.0% |
100.0% |
| 2 |
1.88 |
1.93 |
1.93 |
2 |
93.9% |
96.5% |
96.3% |
| 3 |
2.78 |
2.85 |
2.88 |
3 |
92.6% |
95.0% |
95.8% |
| 4 |
3.57 |
3.73 |
3.75 |
4 |
89.2% |
93.1% |
93.6% |
The results for two other scenes
 |
 |
Scene B4
(3 lights, 3781 spheres, 1 polygon) |
Scene G2
(5 lights, 1169 polygons) |
5. Invitation to collaboration
|
We are ready to discuss any forms of collaboration with those interested
in:
- using T-system in any field where a multiprocessors where applicable;
- further development of T-system, porting to other hardware, implementation
of various programming languages, libraries and applications for T-system.
6. Selected publications on T-system
|
- [NATUG'93] Abramov S.M., Adamovitch A.I., Nesterov I.A., Pimenov
S.P., Shevchuck Yu.V. Autotransformation of
evaluation network as a basis for automatic dynamic parallelizing
// Proceedings of NATUG 1993 Meeting "Transputer: Research and
Application", May 10-11, 1993.
- [RCMS'94] Abramov S.M., Nesterov I.A., Shevchuk Yu.V. T-language.
Preliminary description, RCMS Tech. Report #09/18/1994
- [PACT'95] Adamovich A.I. cT: an
Imperative Language with Parallelizing Features Supporting the Computation
Model "Autotransformation of the Evaluation Network"
// LNCS #964 1995, Parallel computing technologies: third international
conference; proceedings / PaCT-95, St. Petersburg, Russia, September 12
- 25, 1995. Victor Malyshkin (ed), pp. 127-141
- [SIAM'95] I.A.Nesterov, I.V.Suslov., Towards
programming of numerical problems within the system providing automatic
Parallelizing // Proceedings of 7th SIAM conference on parallel
processing for scientific computing, p.716, San-Francisco, CA, 1995.
Most of the publications are FTP-available from Web-page: http://www.botik.ru/~abram/ts-pubs.html.





{kind=link}
{kind=link}
{kind=link}
{kind=link}